用 python 实现一个记忆助手
一、背景
记忆的本质,无非就是重复再重复。为了适配我日常工作与生活中的英语需求,一款辅助提升词汇量的工具应运而生。它不止于背单词,而是万物皆可记,万物皆可背。
市面上很多单词软件都只能背单词,而且是固定词库里面的,不足够开放,这也是我开发该工具的主要原因,要不然就不会重复造轮子了。
二、工具描述
使用方式
- 安装依赖:
- python >= 3.11
pip install tkmacosx
- 执行 make 指令生成软件包「软件包位置:./dist/app.app」
- 数据默认存储在了
~/my_github/memory-assistant-private/v2/data/items.txt,可以通过修改代码修改存储位置
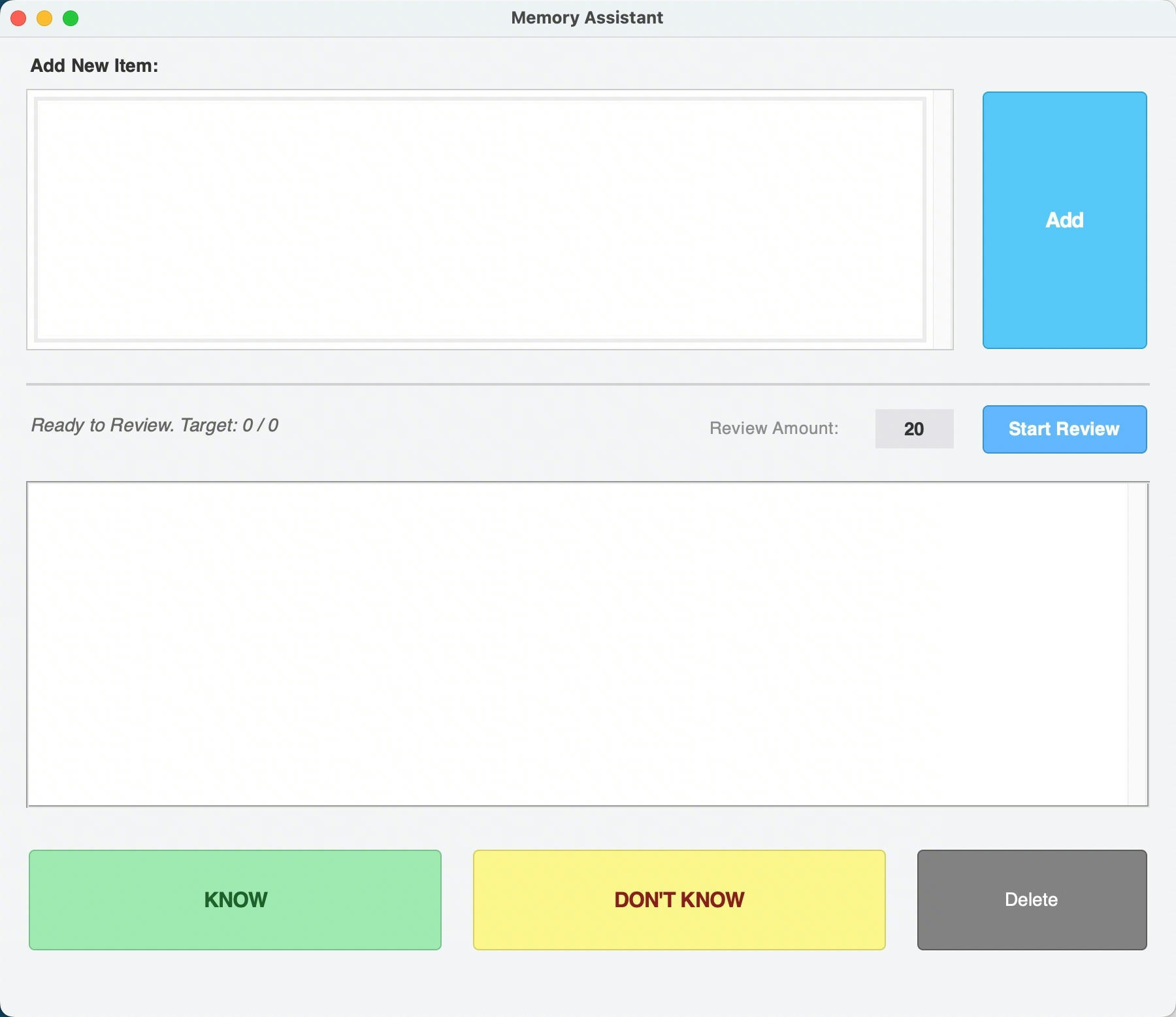
基本功能
- 支持手动添加词条
- 支持生成指定数量的复习词条列表
- 支持词条打标:认识/不认识,并且支持删除
核心算法
这里的算法指的是如何为每个词条生成需要复习的权重,这里参考了艾宾浩斯公式,同时加入了自己的一些自定义指标
参考指标:
- 词条首次添加时间:距离该时间超过 1 天才会生效,越往后对复习权重影响越小
- 词条上次复习时间:距离该时间越长对复习权重影响越大
- 词条的不认识次数:次数越高影响越大
公式:
简单概括就是优先考虑新添加超过一天的词条,其次考虑词条的艾宾浩斯遗忘概率

三、实现
由于是在 mac 电脑上面进行的开发,windows 系统的兼容性还未验证
此外,如果本地加载的 ui 异常,可以考虑升级 python 版本解决,mac 系统和 tkinter 容易出现不兼容问题
功能实现
- 数据存储
首先是数据的存储方式,由于是个人使用,不会有太大的数据量,所有直接用了 text 文本存储。其次是数据的格式,包括不同词条之间的隔离、每条词条内的内容和属性的隔离、属性之间的隔离,最终的隔离方案如下:
- 词条之间的分隔符:·
\n=*==*==*==*==*==*==*==*==*==*=\n - 词条与属性之间的分隔符:
\n--------------------\n - 属性之间的分隔符:
,
存储示例:
1 | 测试数据 1 |
- 交互逻辑
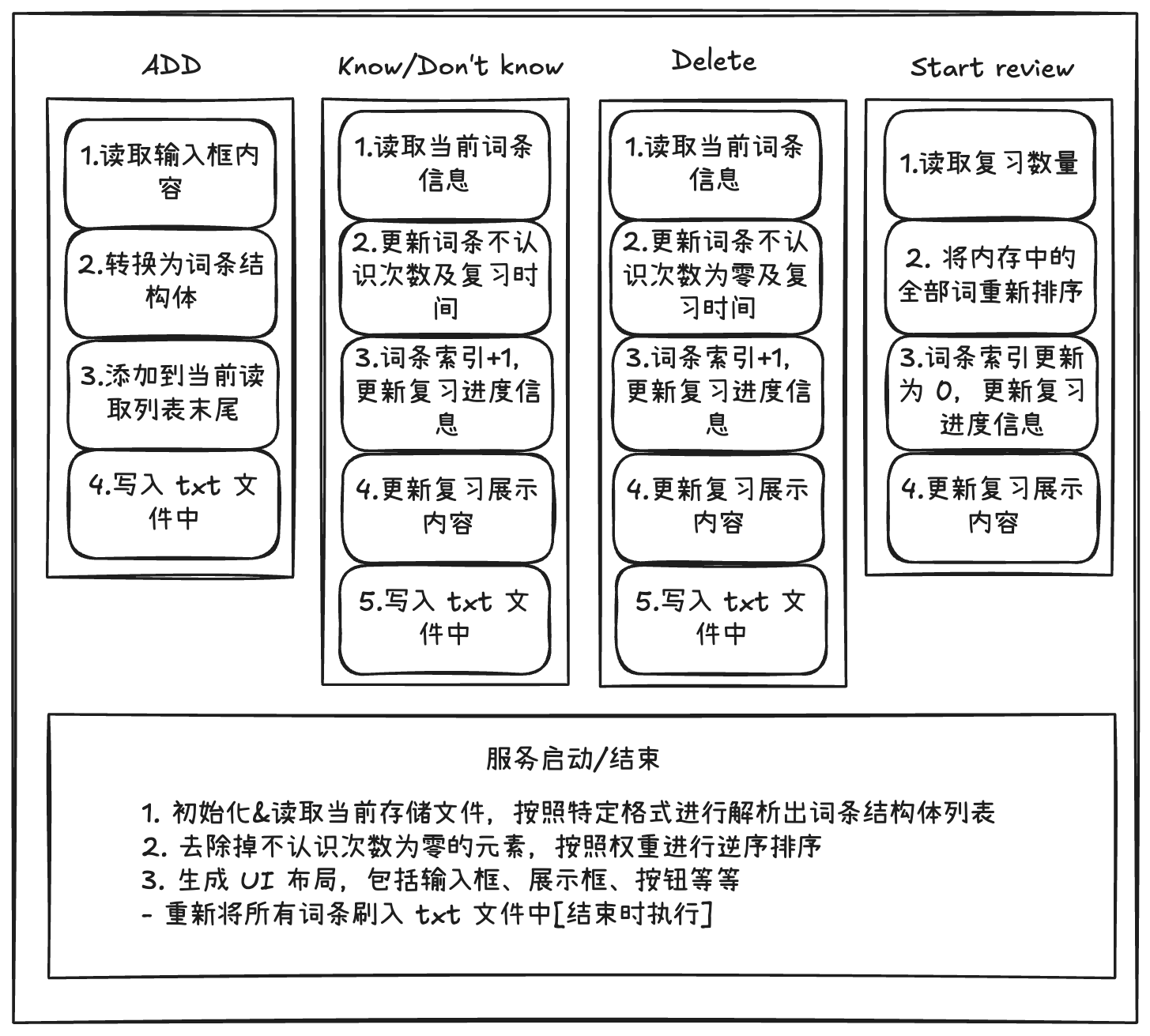
算法实现
直接看代码
1 | def cal_ebbinghaus_with_newness(days_first,days_last, forget_count): |
四、拓展
功能拓展
- 支持账号绑定
- 支持内容分类
- 可以支持非常多的功能,可以参考市面上的单词背诵软件
- ….
技术拓展
- 将 txt 文件存储替换为数据库存储
- 支持云存储
- …..
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Chitian's Blogs!