EVM(以太坊虚拟机)
一、定义
EVM 全称是 Ethereum Virtual Machine ,具备以下特性:
- 虚拟运行环境: 它不直接运行在硬件上,而是作为一个软件层运行在每一个以太坊节点(计算机)中。
- 沙盒化(Sandboxed): EVM 是完全隔离的。在 EVM 中运行的代码(智能合约)无法访问网络、文件系统或其他进程。这保证了即使合约有恶意代码,也不会损害节点本身。
- 统一性: 无论在 Windows、Linux 还是 macOS 上运行以太坊节点,EVM 的执行结果都是完全一致的。
二、工作原理
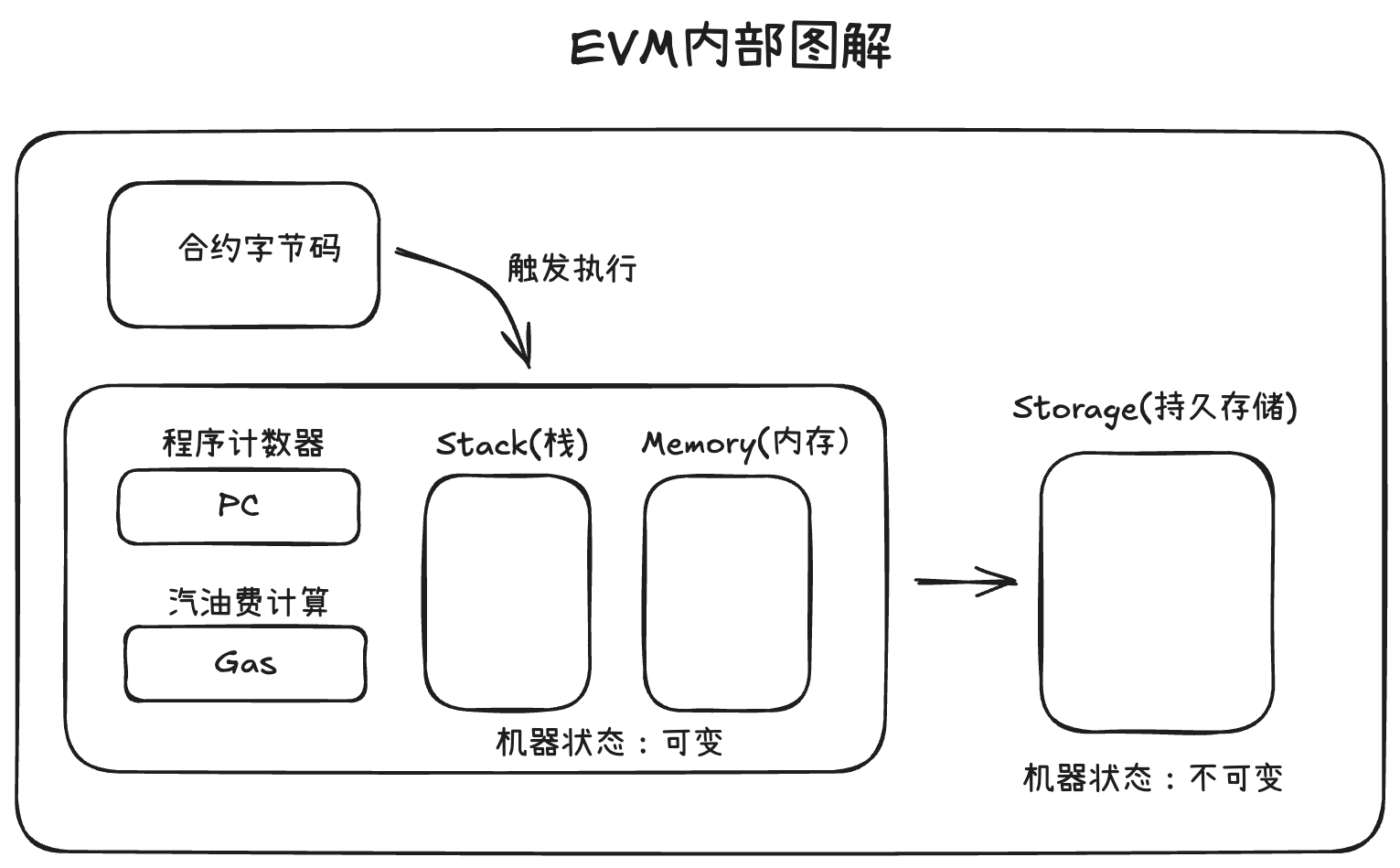
1. 代码的编译与执行流程
- 编写: 开发者写好 Solidity 代码。
- 编译: 编译器将代码转换为 Bytecode(字节码)。这是 EVM 唯一能读懂的语言(一串十六进制数字)。
- 部署: 字节码被作为数据发送到区块链上存储。
- 执行: 当用户调用合约时,EVM 读取这些字节码,并将其分解为 Opcode(操作码) 逐行执行。实际是底层的
switch-case解释器中逐条触发宿主机早已编译好的对应逻辑「比如 go 编写的 geth,把 Opcode 映射成了已经编译好的 go 代码,复用这个高级语言的跨平台特性」
2. 栈式架构
与我们在个人电脑中常用的 x86 架构(基于寄存器)不同,EVM 是基于栈(Stack) 的虚拟机。
- 后进先出 (LIFO): 数据像叠盘子一样,最后放进去的数据最先被取出。
- 操作方式: EVM 指令(如
ADD)会从栈顶弹出两个数字,相加,然后将结果压回栈顶。 - 优点: 这种架构更容易实现,且对指令长度要求更短(不需要指定操作数的地址,默认就在栈顶)。
3. 数据存储空间
EVM 在执行时有三种主要的数据存储区域,它们的成本和用途各不相同:
(这块其实在学习到 solidity 语言的时候会理解的更深刻一些)
| 存储类型 | 特点 | 成本 (Gas) | 用途 |
|---|---|---|---|
| Stack (栈) | 免费、极快,但空间很小(仅1024层)。 | 低 | 用于运算过程中的临时变量交换。 |
| Memory (内存) | 临时存储,合约执行完即清空。数据量越大越贵。 | 中 | 用于存储函数参数、返回值、临时数组。 |
| Storage (存储) | 永久存储在区块链上。全网同步,最昂贵。 | 极高 | 用于存储合约的状态变量(如用户的代币余额)。 |
Stack(栈)
在堆栈中,每个元素长度为256位(32字节),最大深度为1024元素,但是每个操作只能操作堆栈顶的16个元素。这也是为什么有时Solidity会报Stack too deep错误。
问题1 :为什么最大深度 1024,却只能一次性操作 16 个元素呢?
首先,目前能够操作 16 个元素的只有有 SWAP16和 DUP16,如果想要操作第 17 个元素,那么需要增加指令 SWAP17 或 DUP17 了。其次,前面提到过,Opcode 最多有 256 个,资源有限,是十分珍贵的,所以不能随意扩充,而且 16 个元素已经可以满足大部分场景了。
聪明的你可能想到了,为什么不能直接定义 SWAP 和 DUP 两个不带数字后缀的指令,然后字节码中该指令后面紧跟着的就代表元素位置呢,相关的法案EIP-663已经在 24 年提出来了,目前还未落实。
问题2:Stack too deep 是如何造成的?
造成该问题的根本原因,就是仅仅操作 16 个元素无法满足我的代码逻辑的实现了,比如下面的 solidity 程序,函数内部定义了超过 16 个元素的,然后想要访问第 17 个元素就会报错,下面附带了一段程序。其中很容易想到的优化方式就是把变量从栈移到内存中去即可
1 | // SPDX-License-Identifier: MIT |
Memory(内存)
堆栈虽然计算高效,但是存储能力有限,因此EVM使用内存来支持交易执行期间的数据存储和读取。EVM的内存是一个线性寻址存储器,可以把它理解为一个动态字节数组,可以根据需要动态扩展。它支持以8或256 bit写入(MSTORE8/MSTORE),但只支持以256 bit读取(MLOAD)。
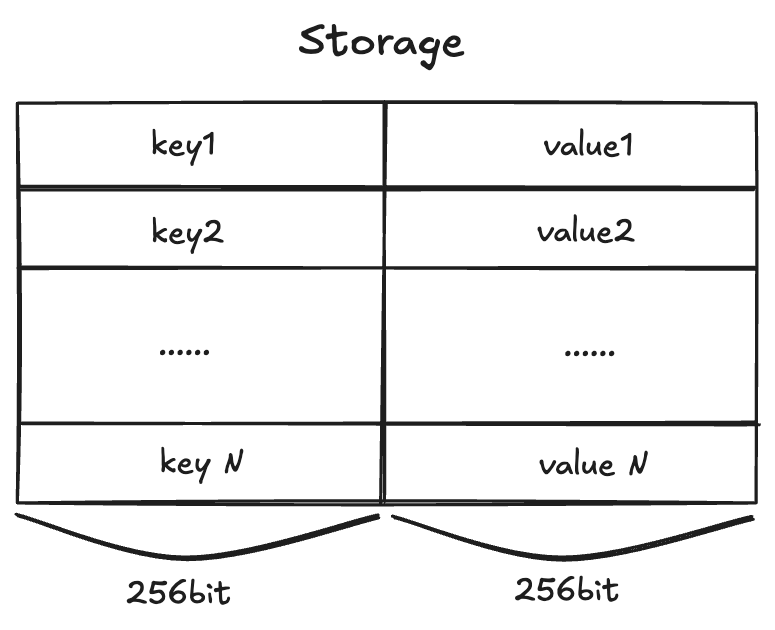
Storage(存储)
EVM的账户存储(Account Storage)是一种映射(mapping,键值对存储),每个键和值都是256 bit的数据,它支持256 bit的读和写。这种存储在每个合约账户上都存在,并且是持久的,它的数据会保持在区块链上,直到被明确地修改。
对存储的读取(SLOAD)和写入(SSTORE)都需要gas,并且比内存操作更昂贵。这样设计可以防止滥用存储资源,因为所有的存储数据都需要在每个以太坊节点上保存。
4. Gas 机制 (燃料)
由于 EVM 是图灵完备的(允许循环),如果有人写了一个死循环(while(true)),全网节点都会卡死。为了解决这个问题(停机问题),以太坊引入了 Gas。
- 付费计算: 每一个 Opcode(如加法、乘法、存储数据)都有固定的 Gas 成本。
- 耗尽即停: 交易发送者必须预付 Gas。如果代码执行中 Gas 耗尽,EVM 会立即停止执行,回滚所有状态更改,但不退还已消耗的 Gas。
三、Opcode
Opcode 是 EVM 的机器语言,是 1 字节的指令,最多能有 256 个指令($2^8$),目前以太坊定义了约 140 多个,其余未定义。直接去记0x01 之类的字节码是比较困难的,所以每一个指令都有对应的英文缩写,类似于汇编语言,将 2 进制的 0,1 转换成我们更容易理解的符号而已
1. 基础操作指令
定义自己的 OpCode 的原因是:为了日后拓展其他语言,不只 solidity 也能支持其他语言。更容易做适配以太坊环境的拓展,比如 gas 数量和 OpCode 的绑定
Opcode明细在这里查看
1.1 栈操作 (Stack Manipulation)
这是 EVM 最频繁使用的指令,用于数据的搬运。
| 字节码 | 指令名称 | 指令解释 | 基础 Gas |
|---|---|---|---|
0x50 |
POP | 从栈顶移除 1 个元素 | 2 |
0x60 |
PUSH1 | 将随后的 1 字节数据压入栈顶 | 3 |
0x60…0x7F |
PUSH1-32 | 将随后的 2~32 字节数据压入栈顶 | 3 |
0x80 |
DUP1 | 复制栈顶第 1 个元素并再次压入栈 | 3 |
0x81…0x8F |
DUP2-16 | 复制栈深处第 N 个元素到栈顶 | 3 |
0x90 |
SWAP1 | 交换栈顶第 1 和第 2 个元素 | 3 |
0x91…0x9F |
SWAP2-16 | 交换栈顶第 1 和第 N+1 个元素 | 3 |
问题:已知栈元素基本长度就是 32 个字节,只保留 PUSH32 不就可以了么?
PUSHN 指令的执行逻辑是 将后面 N 个字节长度的字节码压入栈中
- 用 PUSH1 0x01:字节码占
0x60 0x01(2 字节)- 若只有 PUSH32:需要写成
0x7f 0x0000000000000000000000000000000000000000000000000000000000000001(33 字节)字节码的长度变长了,那么需要的Gas 费用也会更高了,已知 200Gas/Byte
1.2 算术运算 (Arithmetic Operations)
用于基本的数学计算。
| 字节码 | 指令名称 | 指令解释 | 基础 Gas |
|---|---|---|---|
0x01 |
ADD | 加法 (a + b) |
3 |
0x02 |
MUL | 乘法 (a * b) |
5 |
0x03 |
SUB | 减法 (a - b) |
3 |
0x04 |
DIV | 整数除法 (a / b),分母为0结果为0 |
5 |
0x06 |
MOD | 取模/余数 (a % b) |
5 |
0x0A |
EXP | 指数运算 (a ** exponent) |
10 + (50 * 字节数) |
0x01 |
ADDMOD | 加法取模 (a + b) % N |
8 |
0x02 |
MULMOD | 乘法取模 (a * b) % N |
8 |
1.3 比较与逻辑 (Comparison & Logic)
结果通常为 1 (True) 或 0 (False)。
| 字节码 | 指令名称 | 指令解释 | 基础 Gas |
|---|---|---|---|
0x10 |
LT | 小于 (a < b) |
3 |
0x11 |
GT | 大于 (a > b) |
3 |
0x14 |
EQ | 等于 (a == b) |
3 |
0x15 |
ISZERO | 是否为零 (a == 0) |
3 |
0x16 |
AND | 按位与 (&) |
3 |
0x17 |
OR | 按位或 (|) |
3 |
0x19 |
NOT | 按位取反 (~) |
3 |
1.4 内存与存储 (Memory & Storage) - 最重要且最贵
理解这些指令对优化 Gas 至关重要。
| 字节码 | 指令名称 | 指令解释 | Gas (估算) |
|---|---|---|---|
0x51 |
MLOAD | 从内存读取 32 字节 | 3 + 内存扩展费 |
0x52 |
MSTORE | 向内存写入 32 字节 | 3 + 内存扩展费 |
0x53 |
MSTORE8 | 向内存写入 1 字节 | 3 + 内存扩展费 |
0x54 |
SLOAD | 从**存储(硬盘)**读取数据 | 100 (热读) / 2100 (冷读) |
0x55 |
SSTORE | 向**存储(硬盘)**写入数据 | 2900 (热写) / 20000 (新存) |
0x20 |
SHA3 | 计算 Keccak256 哈希值 | 30 + (6 * 字节数) |
_注:存储操作(SLOAD/SSTORE)的价格会根据 EIP(如 EIP-2929)经常调整,且取决于该槽位是否已被访问过(冷/热)。
问题:其中的冷热表示什么?
在以太坊的底层代码(客户端如 Geth)中,每个交易执行时都会维护一个 Access List(访问列表/缓存集合)。这里的冷、热由是否使用了 EVM 缓存决定,用到了就是热,否则冷。虽然热操作节省 Gas,但是只能针对单笔交易有效。示例:
- 交易 A 读取了变量
x-> 冷读(付 2100)。- 交易 A 再次读取变量
x-> 热读(付 100)。- (交易 A 结束,区块打包)
- (Access List 被清空)
- 交易 B 开始,读取变量
x-> 又是冷读(付 2100)。
1.5 环境信息 (Environmental Information)
获取当前交易、区块或发送者的上下文信息。
| 字节码 | 指令名称 | 指令解释 | 基础 Gas |
|---|---|---|---|
0x30 |
ADDRESS | 获取当前合约地址 (address(this)) |
2 |
0x31 |
BALANCE | 获取某地址余额 | 100 (热) / 2600 (冷) |
0x32 |
ORIGIN | 交易发起者 (tx.origin) |
2 |
0x33 |
CALLER | 直接调用者 (msg.sender) |
2 |
0x34 |
CALLVALUE | 随交易发送的 ETH (msg.value) |
2 |
0x36 |
CALLDATASIZE | 输入数据的大小 | 2 |
0x3A |
GASPRICE | 当前交易 Gas 价格 (tx.gasprice) |
2 |
0x42 |
TIMESTAMP | 当前区块时间戳 (block.timestamp) |
2 |
1.6 流程控制 (Flow Control)
决定代码跳转到哪里执行。
| 字节码 | 指令名称 | 指令解释 | 基础 Gas |
|---|---|---|---|
0x56 |
JUMP | 无条件跳转到指定位置 | 8 |
0x57 |
JUMPI | 条件跳转 (if (condition) jump) |
10 |
0x58 |
PC | 获取当前程序计数器位置 | 2 |
0x5B |
JUMPDEST | 标记一个合法的跳转目的地 | 1 |
0x00 |
STOP | 停止执行,成功退出 | 0 |
0xFD |
REVERT | 停止执行,回滚状态,返回数据 | 0 + 内存消耗 |
0xF3 |
RETURN | 停止执行,保留状态,返回数据 | 0 + 内存消耗 |
1.7 系统操作 (System Operations)
与其他合约交互。
| 字节码 | 指令名称 | 指令解释 | 基础 Gas |
|---|---|---|---|
0xF0 |
CREATE | 创建新合约 | 32000 + 其它 |
0xF1 |
CALL | 调用其他合约 | 100 (热) / 2600 (冷) + 其它 |
0xF4 |
DELEGATECALL | 委托调用 (保留上下文) | 100 (热) / 2600 (冷) + 其它 |
0xFA |
STATICCALL | 静态调用 (不允许修改状态) | 100 (热) / 2600 (冷) + 其它 |
0xFF |
SELFDESTRUCT | 销毁合约并发送余额 (已弃用/改动) | 5000 + 其它 |
2. 理解 Opcode 的重要性
平时写 Solidity 不需要直接写 Opcode,但理解它有巨大好处:
- 省钱 (Gas Optimization):
- 知道了
SSTORE很贵,就会尽量减少写状态变量,改用Memory里的变量做中间计算,最后一次性写入Storage。 - 知道
0值和非0值处理成本不同,就会注意变量初始化。
- 知道了
- 理解黑客攻击:
- 很多攻击(如 Reentrancy 重入攻击)在 Solidity 层面看很抽象,但在 Opcode 执行流层面(
CALL之后控制权移交,然后再次CALL)就非常清晰。
- 很多攻击(如 Reentrancy 重入攻击)在 Solidity 层面看很抽象,但在 Opcode 执行流层面(
- 内联汇编 (Inline Assembly):
- 在 Solidity 里可以使用
assembly { ... }直接写 Opcode。这能绕过 Solidity 的一些限制,或者做极致的性能优化。
- 在 Solidity 里可以使用
优化示例
A. 绕过数组边界检查 (Bypassing Array Bounds Check)
在 Solidity 中,每次访问数组元素 arr[i],编译器都会自动插入一段 Opcode 来检查 i < arr.length。如果在 for 循环中,这个检查会重复执行无数次,浪费大量 Gas。
优化原理: 使用汇编直接计算内存地址并读取,跳过检查。
普通 Solidity 写法:
1 | function sumSolidity(uint[] memory arr) external pure returns (uint sum) { |
Opcode 优化写法:
1 | function sumAssembly(uint[] memory arr) external pure returns (uint sum) { |
收益: 在大循环中,每次迭代可节省约 100-200 Gas
B. 利用草稿区避免内存分配
Solidity 的 string 和 bytes 类型非常昂贵,因为它们涉及大量的内存复制,如果设计内存空间不大,可以直接在草稿区操作
场景: 比如需要哈希两个输入参数。
普通 Solidity 写法:
1 | // 数据会先被复制到 Memory,产生内存扩展费和复制费 |
Opcode 优化写法:
1 | function hashAssembly(uint a, uint b) external pure returns (bytes32 result) { |
收益: 节省了 abi.encodePacked 带来的内存分配(MSTORE)和指针移动开销,且没有触碰 Free Memory Pointer。
C. 判断是否为合约地址 (isContract)
这是一个非常常见的检查。Solidity 标准库通常会用 addr.code.length > 0。
普通 Solidity 写法:
1 | function isContract(address account) external view returns (bool) { |
Opcode 优化写法:
1 | function isContractAssembly(address account) external view returns (bool result) { |
收益: 避免了 Solidity 包装器带来的一些栈操作和类型转换开销,更加直接。
方式很多,不一一列举了….
参考: